

Alteryx daje możliwość zanurzenia się w oceanie danych. Mówiąc mniej poetycko, możemy sięgnąć do danych w dowolnej postaci, czyli plików, relacyjnych baz danych, hurtowni danych, ale również do danych dostępnych w Internecie. Tej ostatniej możliwości postanowiliśmy poświęcić ten obszerny artykuł dlatego, że dane pochodzące z zasobów Internetu mogą być bardzo wartościowe, a cała procedura nie jest skomplikowana.
Różne usługi webowe lub strony www udostępniają dane poprzez interfejs API. Skrót API oznacza Application Programming Interface (interfejs programowania aplikacji) i jest używany wszechobecnie do komunikowania się między aplikacjami.
Za przykład można podać spotkanie dwóch osób z różnych zakątków świata na przykład z Polski i Brazylii. Osoby te żyją w różnych kręgach kulturowych, posługują się różnymi językami ojczystymi, ale mogą się komunikować też w międzynarodowym, zrozumiałym dla obu stron, języku czyli załóżmy angielskim. Podobnie jest w przypadku komunikacji poprzez API. W praktyce, kiedy używa się programowalnych API, żądanie tzw. call jest po prostu adresem URL, a odpowiedź jest często w formacie JSON lub xml. W jaki sposób łączyć się do API i jakich poleceń można użyć znajdziemy w dołączonej do web API dokumentacji. To jest najczęściej słownik, z którego możemy nauczyć się sposoby komunikowania poprzez API.
Dane z Internetu, przykładowe możliwości pobrań przez API
Alteryx wykonuje pracę polegającą na pozyskaniu danych za pomocą web API i przetworzeniu ich na coś użytecznego. Co więcej, przepływ pracy (sekwencja narzędzi) jest bardzo podobna przy użyciu dowolnego API.
Na przykład, dane o postaciach z sagi Star Wars…
Dane o liczbie zakażeń, zgonów z tytułu COVID-19…

Geokodowanie adresów poprzez Google Maps API.
Przykładów wykorzystania jest bez liku.
Jeśli chcecie poćwiczyć jak połączyć z interfejsem API to polecamy sprawdzić listę darmowych i publicznych API dostępnych na stronie RapidAPi.
Jak widać na powyższych przykładach, przepływy używają mniej więcej tych samych narzędzi. Jedyną różnicą jest kolejność narzędzi oraz kilka dodatkowych narzędzi na końcu przepływu pracy wykorzystywanych do formatowania specyficznych danych, na przykład przy transpozycji nagłówków lub filtrowaniu pewnych metadanych.
Jak połączyć się z endpoint API w Alteryx?
Omówimy ogólny proces narzędzie po narzędziu związany z uzyskaniem poprawnie sformatowanych danych. W tym przykładzie używam interfejsu API do bazy zawierającej dane finansowe spółek publicznie notowanych, które gromadzi Yahoo Finance.
Wyciągniemy ostatnie dzienne notowania firmy Apple. Wszystkie szczegóły znajdziecie tutaj
Jeśli chcecie odbudować ten przykładowy przepływ należy zarejestrować się w serwisie RapidAPI.
Każde połączenie do endpoint API wymaga wykorzystania przynajmniej trzech narzędzi:
Text Input + Download + JSON Parse
1.Text Input Tool
Wszystko zaczyna się od osadzenia Text Input.

Pierwszym (i często najtrudniejszym) krokiem jest znalezienie prawidłowego adresu URL, który zostanie użyty do wysłania żądania po dane. Adresy API różnią się od siebie i często konieczne jest przebrnięcie przez dokumentację i przykładów, jak go używać. Ponadto, niektóre API wymagają klucza API, który często otrzymamy dopiero po rejestracji lub akceptacji wniosku (np. API Strava, API TripAdvisor). Zalecamy korzystanie z API, które są dobrze udokumentowane wtedy cały proces będzie dużo łatwiejszy.
Alteryx korzysta z żądania w formacie HTTP. Zapis żądania przykładowo wygląda tak:
GET /stock/v3/get-historical-data?symbol=AMRN®ion=US HTTP/1.1
X-Rapidapi-Key: [Tutaj powinien znaleźć się Twój klucz API]
X-Rapidapi-Host: apidojo-yahoo-finance-v1.p.rapidapi.com
Host: apidojo-yahoo-finance-v1.p.rapidapi.com
W naszym przykładzie adres URL do endpoint API będzie wyglądał tak:
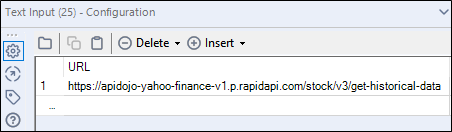
https://apidojo-yahoo-finance-v1.p.rapidapi.com/stock/v3/get-historical-data
2. Download Tool
Drugim obligatoryjnym narzędziem jest Download Tool. Wskazujemy pole z adresem URL, jeśli mamy jedno zostanie wybrane automatycznie.

Jeśli jest wymagany, musimy przekazać klucz API. Możemy to zrobić na dwa sposoby.
1/ Klucz może być dołączony do adresu URL w poprzednim kroku (coś jak https://apidojo-yahoo-finance-v1.p.rapidapi.com/stock/v3/get-historical-data&x-rapidapi-key=[twój klucz API])
Zwróćmy uwagę na połączenie tekstów operatorem &.
2/Klucz może być włączony jako osobna kolumna z nagłówkiem kolumny X-Rapidapi-Key i wartością równą kluczowi. Robimy to w ustawieniach Headers

Dodatkowo możemy wprowadzić warunki ograniczające zakres zapytania jak na przykład symbol spółki Apple (AAPL) oraz region (US). Ograniczenia definiujemy w zakładce Payload.
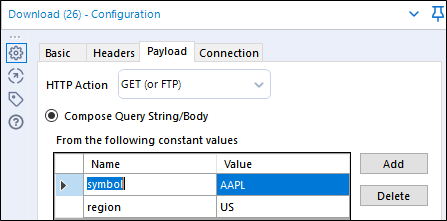
Jeśli puścimy nasz przepływ i wszystko przebiegło bez problemów powinniśmy otrzymać wartość nagłówka HTTP/1.1 200 OK
W polu DownloadData znajdują się dane w formacie oferowanym przez API, w tym przypadku i najczęściej będzie to format JSON.

Po uruchomieniu przepływu będziemy mieli wszystkie dane ale będą zamknięte w jednej komórce. Możemy je rozszerzyć do formatu tabelarycznego za pomocą narzędzia JSON Parse.
Zwrócone dane będą w postaci, która wymaga dalszych transformacji. Jednak mamy pewność, że nasze żądanie zostało zaspokojone.
Fragment wyniku
{„prices”:[{„date”:1614107394,”open”:123.76000213623047,”high”:124.98999786376953,”low”:118.38999938964844,”close”:124.94999694824219,”volume”:117967326,”adjclose”:124.94999694824219},{„date”:1614004200,”open”:128.00999450683594,”high”:129.7200012207031…
3. JSON Parse Tool
Narzędzie JSON Parse jest proste w użyciu. Wystarczy wybrać pole, które zawiera wszystkie dane JSON – jest to tekst z wszystkimi zagnieżdżonymi nawiasami klamrowymi.

Jeśli nie zmienisz nazwy ręcznie, pole zostanie nazwane DownloadData. Wybierz opcję Output values into a single string field, chyba że chcesz rozdzielić wszystkie typy danych na różne kolumny. Po uruchomieniu tej opcji nasze dane będą wyrównane do pionu w jednej kolumnie, tak jak to ma miejsce w przypadku pojedynczej kolumny,
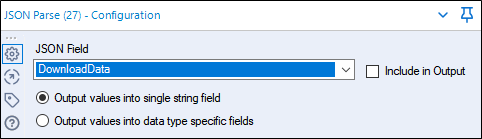
Często pojawiają się inne kolumny powtarzających się danych, takie jak URL i DownloadHeaders, ale bardziej interesują nas te dwie kolumny pokazane poniżej. Stąd już tylko kwestia formatowania, aby uzyskać nasze dane w logicznym formacie tabeli.
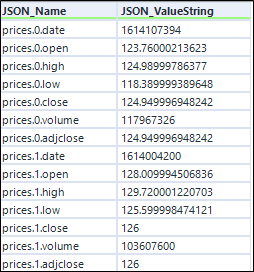
4. Text to Columns Tool
Widzimy, że mamy kilka użytecznych pól połączonych razem w kolumnie JSON_Name. Najprostszym sposobem na rozdzielenie ich jest użycie narzędzia Text to Columns.

Wybierz JSON_Name jako pole do podziału, użyj kropki jako delimitera i wybierz do ilu kolumn chcesz się podzielić. Na przykład, rozdzielimy prices.0.date’, ‘prices.0.open’, itd. na trzy kolumny, które następnie automatycznie otrzymają nazwy JSON_Name1, JSON_Name2 i JSON_Name3 (chyba że w konfiguracji podano inaczej). Teraz mamy kolumny dla danych/metadanych, grupowania i nagłówków.
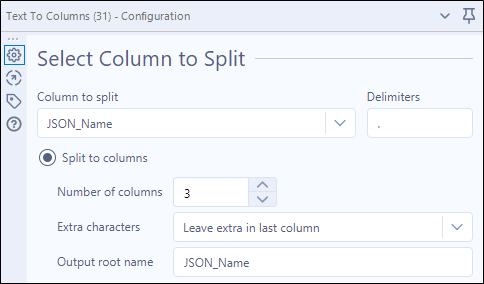
Wynik rozdzielenia tekstu do kolumn
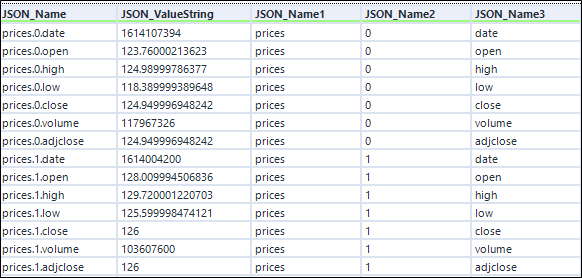
5. Filter Tool
Kolejne operacje są już specyficzne dla tego konkretnego przypadku. Najczęściej będziecie dodatkowo korzystać z filtrowania rekordów i transpozycji wierszy do kolumn po to by stworzyć tabelę przestawną łatwiejszą w interpretacji.
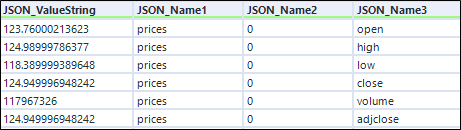
Użyłem filtra, aby pozbyć się wartości różnych od słowa prices w polu JSON_Name1.

[JSON_Name1] = „prices”
Wyłączam też pole daty. Datę dołączę poprzez osobny krok.
[JSON_Name3] != „date”
Filtr ten jest bardzo użyteczny, ponieważ nie tylko oddziela główne dane, ale także metadane będą kierowane na output F. Może to być użyteczne przy śledzeniu numerów stron lub całkowitej liczby rekordów podczas uruchamiania makr iteracyjnych.
6.Cross Tab
Crosstab jest kluczowym elementem w umieszczaniu naszych danych w logicznym formacie tabeli. W tej chwili mamy dane w formie tabeli płaskiej.
Użyjemy zatem Cross Tab Tool po to by przekształcić tą tabelę tak aby wszystkie pasujące dane znajdowały się w osobnych kolumnach.
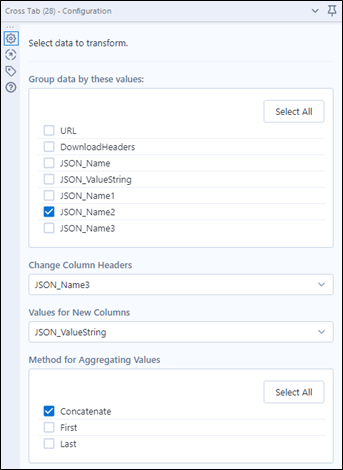
Nowe nagłówki znajdują się w polu JSON_Name3, wartość w JSON_ValueString, które pogrupujemy według JSON_Name2 co odpowiada kolejnym datom.
Grupowanie decyduje jakie wartości pozostaną w wierszach.
Po zastosowaniu Cross Tab otrzymujemy:
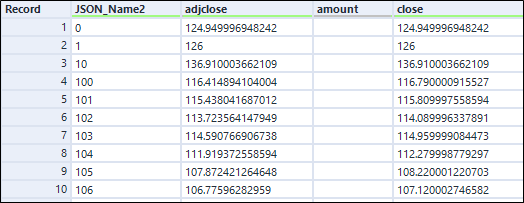
Wygląda jak to czego oczekiwaliśmy. Zauważ również, że liczba rekordów została zmniejszona kilkukrotnie, ponieważ tyle nagłówków kolumn było pierwotnie ułożonych jeden za drugim.
W kolejnym kroku pozbędziemy się nadmiarowych kolumn i dodamy daty.
7. Clean-up
Brakuje nam pola daty. Wiem jednak z dokumentacji, że data ułożona jest malejąco od daty bieżącej reprezentowanej przez wartość 0 w polu JSON_Name2 dla [JSON_Name3]= „date” z kroku 5. Filter.
Użyję Formula Tool do stworzenia kalkulacji dla daty.
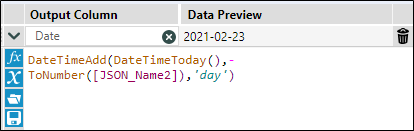
Datę dodam poprzez Join Tool do tabeli przestawnej. Dodatkową zaletą Join Tool jest możliwość odznaczenia pól, których nie chcemy widzieć w naszym modelu.
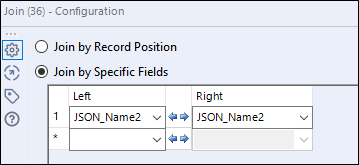
Finalny krok to posortowanie dat malejąco i voila! Dane wyglądają czysto i nadają się do dalszej analizy bądź wizualizacji.

8. Output Data
Na koniec dane możemy wyeksportować wynik jako arkusz kalkulacyjny lub plik .hyper i już możemy obejrzeć je w Tableau!
Chociaż niektóre z tych ostatnich kroków mogą się różnić w zależności od Twojego API, ale ogólnie rzecz biorąc, wszystkie przepływy pracy Alteryx, które pozyskują dane za pomocą API, przechodzą ten sam ogólny proces: 1. Wprowadzenie adresu URL API, 2. Pobranie danych poprzez Download Tool, 3. Przetworzenie wyniku z JSON, 4. Podział tekstu do kolumn, 5. Odfiltrowanie metadanych, 6. Przebudowanie do tabeli przestawnej, 7. Sformatowanie i 8. Eksport do pliku .xlsx lub narzędzia BI.
Szczęśliwego żeglowania po oceanie danych😊
-2%201.webp)







