

W tym artykule postaramy się przybliżyć czym jest analiza RFM i jej implementację w Pythonie. Całość będzie zaprogramowana właśnie w tym języku.
Czym jest analiza RFM?
RFM jest to technika segmentacji klientów w oparciu o parametry Recency, Frequency oraz Monetary. Szeroko stosowana w marketingu pozwala dzielić klientów na grupy bardziej lub mniej podatne na promocję, czy innego rodzaju działania skierowane ku klientowi. Metoda RFM pozwala analizować zachowania odbiorców i tym samym umożliwia odpowiednie działanie firmy. Jej zastosowanie można odnaleźć na różnych polach, nie tylko marketingowych, ale w tym artykule skupię się na użyciu jej w tej właśnie branży.
Opiera się ona na wcześniejszych decyzjach danego klienta, dlatego tak ważne jest posiadanie bogatej historii danych.
Składowe RFM
Recency – mówi, ile czasu minęło od ostatniego zakupu produktu przez klienta. Im wyższy wskaźnik tym lepiej, istnieje większa szansa, że pojawi się on ponownie w najbliższym okresie
Frequency – odpowiada na pytanie jak często klient dokonuje zakupu
Monetary – kwestia niemniej istotna niż pozostałe dwie, tj. ile pieniędzy dany klient wydaje
Przygotowanie danych w Python
Dane są do pobrania z serwisu Kaggle. Link do zbioru danych.
Większa część analizy zostanie przeprowadzona po stronie Python. Szczególnie przydatne może to być dla użytkowników dobrze czujących się w programowaniu proponowanym przez to narzędzie. Jest to rozszerzenie do którego niezbędne jest posiadanie Jupyter’a (notebooka do pisania kodu).
Zostaną użyte jedynie podstawowe biblioteki, tj. NumPy, Pandas, MatPlotLib oraz DateTime.
Początkowa eksploracja danych
Dane pobrane z serwisu kaggle posiadają 125 tysięcy rekordów, trzy kolumny. Wyglądają one następująco:

Pobierając zestaw danych najważniejsze to dobrze się z nim zapoznać. Kilka podstawowych komend (do obejrzenia w pliku z kodem) informuje nas o tym, że w utworzonej przez nas tabeli znajdują się trzy kolumny oraz indeks. Dane posiadają 125 tysięcy rekordów, a typ danych jest odpowiedni do dalszej analizy. Nasza tabela wygląda tak:
Widzimy ID klienta, datę transakcji oraz jej wartość w nieustalonej walucie.
Horyzont czasowy jest tutaj najistotniejszy, tym samym warto ustalić zakres dat owych transakcji. Będzie nam to potrzebne do wyliczenia dwóch wartości z analizy RFM, tj. Recent oraz Frequency.

Zaczynamy zatem od połowy maja 2011 roku, kończąc na połowie marca roku 2015. Punktem wyjścia niech będzie zatem dzień 2015-03-16. Dla komercyjnego użycia, można zastosować komendę today(), która w dynamiczny sposób ustali punkt ostatniego dnia.
Etap eksploracji jest zatem zakończony, z danych tabel jesteśmy w stanie utworzyć wszystkie czynniki RFM, uprzednio je transformując.
Transformacja danych
Do wartości R, potrzebujemy różnicy pomiędzy ustaloną datą, a datą transakcji. Obliczamy zatem różnice w dniach pomiędzy obiema datami i zapisujemy w kolumnie days, jako wartość liczbową.
Na tym etapie możliwym jest również ograniczenie liczby rekordów, ze względu na ostatnią datę wykonania transakcji. Jeżeli uznamy rozpiętość czteroletnią, jaką zbyt duża możemy to zmienić. W przypadku tej analizy pozostawię tę kwestię niezmienioną.
Wyliczamy zatem poszczególne składniki za pomocą podstawowych funkcji w połączeniu z grupowaniem ID klienta.
- Dla uzyskania wartości Recency stosujemy funkcję min() na kolumnie days, obliczając ile dni minęło od ostatniej transakcji.
- Dla Frequency stosujemy len(), na customers_id obliczając ile razy pojawił się w rejestrze dany klient
- Dla Monetary sumujemy wartości z kolumny tran_amount.

Końcowym efektem, po zmianie nazw kolumn, jest tabela:

Ma już ona jedynie niecałe 7 tysięcy wierszy, a więc unikalnych klientów.
Nadawanie wartości
Analiza RFM nie polega na operowaniu na wartościach bezpośrednio uzyskanych z zestawu danych. Zakres wartości zamyka się w zakresie od 1 do 5. Tym samym następnym zadaniem jest nadanie owych wartości naszym czynnikom. Do tego celu zastosowałem kwantyle. Odpowiednio dla ¼,1/2 oraz ¾. Ten zabieg pozwala uzyskać zakres od początku do pierwszego kwantylu, od pierwszego do połowy, od połowy do trzeciego kwantylu oraz od trzeciego do końca przedziału. Razem pięć przedziałów dla pięciu wartości. W języku Python bardzo łatwo owe kwantyle uzyskać. Nadajemy wagi z kolejnością od najwyższej do najniższej, tj. najwyższa wartość oznacza najlepszą. Warto zwrócić uwagę, że najwyższe wartości Monetary oraz Frequency w istocie są wartościami najbardziej pożądanymi, jednak już Recency im niższe, tym lepsze.
Ostatecznie tabela po transformacji wygląda tak:

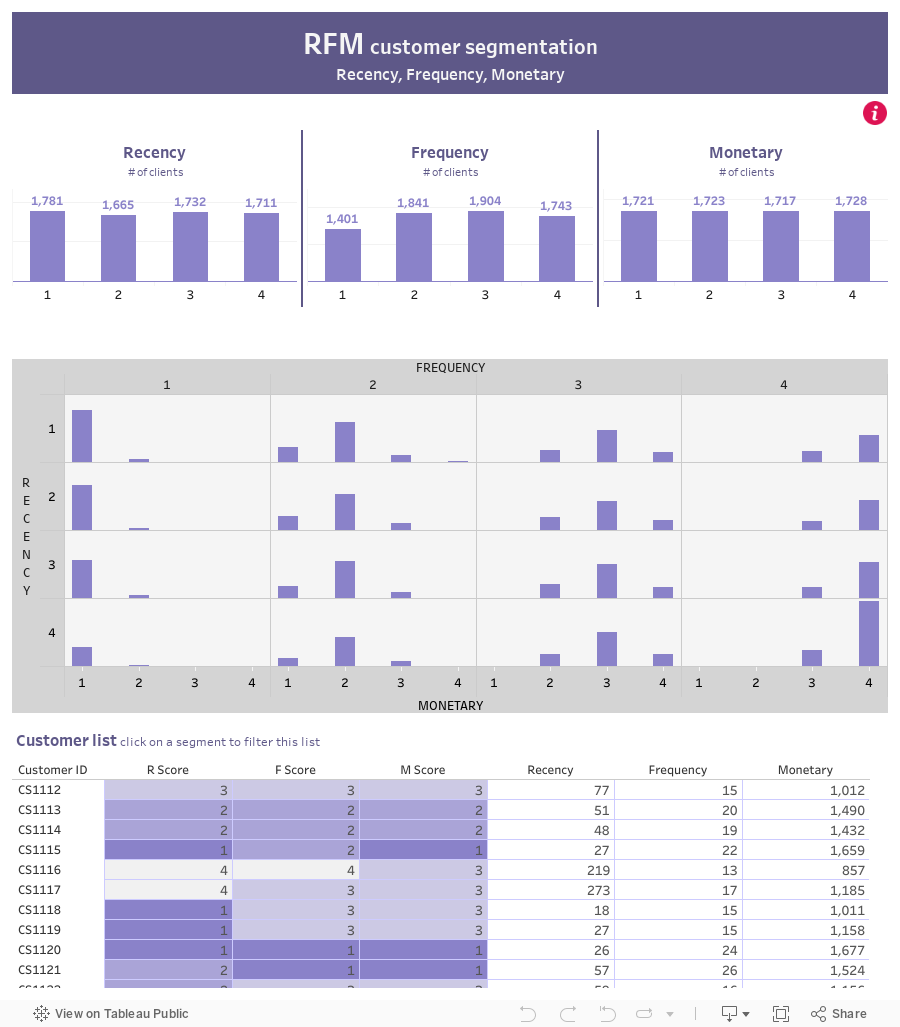
Tableau – podstawowa wizualizacja
Całość można przedstawić w samym Tableau. Staje się ona wtedy w pełni interaktywna oraz przyjazna dla użytkownika. Przykładowa wizualizacja znajduje się poniżej:
*Dostosuj ustawienia i zaakceptuj funkcjonalne pliki cookies, aby wyświetlić interaktywny dashboard w Tableau. Alternatywnie, kliknij link, aby przejść do Tableau Public.
Podsumowanie
Część z bardziej świadomych użytkowników Tableau zapewne zauważy, zresztą słusznie, brak użycia tutaj TabPy, czyli dodatku do samego Tableau, który pozwalałby na użycia Pythona w samym środowisku Tableau. Taka możliwość istnieje, jednak dla samej czytelności kodu, pozwoliłem sobie przedstawić wszystko w Jupterze. Cieszę się, że mogłem zaprezentować tutaj analizę RFM w samym Pythonie. Powodzenia w programowaniu!








